





6月4日,博睿数据「穿透黑盒:AI 大模型评测、成本真相与可观测实践」研讨会圆满结束。研讨会基于《2026年5月中国主流大模型API服务性能及综合表现测评报告》1900+次跨城市全周期真实公网实测数据,彻底颠覆实验室理想跑分结论,客观揭示主流大模型的真实性能短板、场景分化差异与隐形成本差距。同时结合Bonree ONE 4.0核心AI可观测能力,完整输出「大模型科学选型+精细化成本管控+AI应用全链路可观测」一站式落地解法,为企业解决AI落地选型盲区、成本黑盒、运维难等核心痛点。
以下为本次研讨会精华Q&A实录。
全文约6000字,阅读时间约12分钟。
一、为什么做测评:补齐行业短板,
终结AI落地信息真空
Q1:
博睿数据发布《2026 年 5 月中国主流大模型 API 服务性能及综合表现测评报告》的初心是什么?是看到了哪些具体的行业之痛?
A1:当AI大模型从实验室走向企业生产环境,我们发现了一个显著的"信息真空":企业决策者手里只有厂商的宣传材料和碎片化的口碑评价,却没有任何客观、可量化的真实服务数据。这与我们做传统IT监控时面对的场景如出一辙——在没有可观测能力之前,所有的故障判断都靠"感觉"。
具体的行业痛点体现在三个层面:
第一,选型失误成本极高,一旦选错底座模型业务迁移代价巨大;
第二,服务稳定性不透明,厂商宣称的SLA和真实生产环境差距悬殊;
第三,成本失控风险被低估,Token消耗的巨大差异在规模化调用前几乎无感,爆发时才会发现已经超支。
做这份报告,本质上是把博睿数据"让系统透明可见"的核心能力,延伸到了大模型这个新的基础设施层。
Q2:
测评报告如何将用户感受到的体验差异(如首字响应从0.5秒到超时1分钟),变成可信的数字?
A2:"体感"之所以难以量化,根本原因在于缺乏统一的基准场景和可重复的测量手段。
我们的做法是把"体感"拆解成三个可度量的维度:
第一,性能指标量化。首字响应耗时(TTFT)、整体响应耗时、生成速度(tokens/s)都有精确到毫秒级的测量,直接还原用户等待的真实感受;
第二,质量指标量化。引入AI裁判对输出内容进行多维度评分,覆盖逻辑准确性、代码可运行性、任务完成度等,把"答得好不好"这个主观判断转化为0-100的客观分值;
第三,稳定性量化。通过跨城市、跨时段的持续采样——本次超1900次调用——捕捉模型的可用率波动,而不是某一次的"快照"。
这套方法论来源于我们多年来做应用性能监控(APM)的经验积累,本质上是把监控思维迁移到了大模型评测场景。
Q3:
本次测评模拟的是"企业真实智能体调用场景",这个场景设定和学术界常见的benchmark测试有什么本质区别?为什么这个差异很重要?
A3:学术benchmark通常是在理想条件下、通过API单次调用完成的能力测验,关注的是"模型能做到什么"。而企业真实生产环境关注的是"在高并发、有限资源、真实网络条件下,模型能稳定地做到什么"。具体差异体现在三个方面:
首先,网络环境差异——我们选取中国多个核心城市的真实网络环境进行测试,而非云厂商内网直连,还原了企业实际部署的网络延迟;
其次,场景代表性差异——四大场景直接对应企业最高频的智能体应用,而非抽象的能力边界测试;
最后,服务稳定性维度——持续全月采样,捕捉服务在高峰期和低谷期的表现差异,某些模型基础场景可用率100%,但复杂场景可用率骤降至70%以下,这种分裂只有持续测量才能发现。
对企业而言,选型参考应该是"真实服务水平",而非"理想能力上限"。
二、评测方法论,将主观“体感”
转化为客观标准
Q4:
报告选择了代码生成、数学推理、任务规划、幻觉控制四大场景,这些维度是如何确定的?有没有其他候选维度被排除?
A4:场景选择背后有一套清晰的筛选逻辑:这个场景是否与企业核心业务价值直接相关?模型在这个场景的表现差异是否足以影响选型决策?
四大场景的确定逻辑如下:
代码生成对应研发提效和智能运维,是当前企业AI落地渗透率最高的场景;数学推理直接支撑金融测算、数据分析等精度敏感业务;任务规划是智能体(Agent)应用的核心能力,代表AI应用的未来方向;幻觉控制则是所有严谨内容输出场景的基础门槛,直接决定信任度。
确实有一些维度被暂时搁置,例如多模态能力、长文档处理、工具调用精确度等。这些能力同样重要,但当前企业级规模化落地程度相对较低,且测量方法尚需完善。随着企业AI应用深度增加,这些维度会纳入后续版本的评测框架。
Q5:
本次报告基于超1900次真实环境调用,跨越多个核心城市——过程中有没有让团队特别意外的测试结果?
A5:印象深刻的是某些模型的"场景双面性"。以Kimi K2.6 Thinking为例,它在幻觉控制场景拿到了全场最高的90分,展现出极强的知识边界自我认知能力;但同一个模型在代码生成场景的可用率仅有50%,超时频率极高。这种两极分化背后反映的是模型推理机制的特点——深度思考能力强的模型,在高负载的复杂代码生成场景容易因计算资源消耗过大而超时。
另一个意外是Token消耗的悬殊差异。同样完成一个任务,最省的模型(DeepSeek-v4-pro,约2680 tokens/次)和最费的模型(Qwen3.6-plus,约4930 tokens/次)相差接近两倍。在小规模测试中这个差距几乎感觉不到,但对于每天调用数万次的企业来说,这个差距直接体现在月账单上。
数据采集过程中更大的挑战是保持采样环境的一致性——不同城市、不同时段的网络抖动都会影响测量结果,这也是为什么我们坚持做全月持续采样而非一次性快照测试。
Q6:
"AI裁判评分"是本次质量评估的重要手段,但用AI评价AI,业界对此有不少争议。如何确保这个评分机制本身的公正性和可信度?
A6:这是整个报告方法论中投入精力最多的部分。解决思路是"多层校验+透明标准"。
首先,AI裁判采用的是目前公认评测能力较强的主流模型,并给予明确的评分rubric,包括任务完成度、逻辑严谨性、输出完整性等具体维度,避免模糊的主观判断。
其次,对于有客观答案的场景(如数学推理),我们并非完全依赖AI裁判,而是以标准答案比对为主、AI裁判为辅,确保有真值锚点。
第三,我们设计了"裁判一致性检验"机制——对同一批样本多次评分并检查方差,高方差样本会被人工复核。
当然,AI裁判机制并非完美,尤其在创意性、开放性任务上存在局限。这也是我们在报告中明确说明测评方法论局限的原因——透明度本身就是可信度的一部分。
三、测评榜单深度解读,无全能模型,
唯场景最优解
Q7:
DeepSeek-v4-pro以综合均衡性拿下第一,但Kimi在幻觉控制、Doubao在代码生成上都有更亮眼的单场景表现——对企业来说,"综合第一"和"场景第一"哪个更有参考价值?
A7:没有绝对答案,取决于企业的AI应用架构策略。
如果企业是单一大模型策略——选一个模型覆盖所有场景——那"综合第一"是最安全的参考。基于本次测评,DeepSeek-v4-pro在多个场景均衡且Token消耗最低,是目前性价比最优的"通才型"选择。
但如果企业已经或计划构建多模型协同的智能体架构,那"场景第一"才是核心参考。最优解是按场景选模型。从可观测平台的视角,Bonree ONE 4.0支持多类型大模型统一治理,正是为了帮助企业管理这种多模型混用架构。
结论是:当前阶段,追求"一个模型解决所有问题"不现实;有意识地构建多模型协同架构,才是更有竞争力的AI落地方式。
Q8:
Kimi K2.6 Thinking在代码生成场景可用率仅50%,但幻觉控制得了90分。这种能力分裂背后可能是什么原因导致的?
A8:这种"能力分裂"现象在深度推理型模型中相当普遍,背后有几个可能的技术原因。
首先是推理机制的副作用。Kimi K2.6 Thinking采用了深度思考推理机制,这种机制在需要精准、审慎回答的场景表现极为出色——这恰好是幻觉控制高分的来源。但在代码生成这样需要大量token输出且对响应时间敏感的场景,深度推理链消耗的计算资源和时间会显著增加,服务端在高并发时更容易触发超时机制。
其次是服务端容量配置问题。高峰期复杂场景的请求资源消耗远高于基础场景,如果服务端没有针对代码生成类任务做专项扩容,就会出现可用率骤降的问题。
从可观测的角度,这正是AI应用监控的核心价值所在:不是评测一次就完成选型,而是持续追踪模型在生产环境中的真实表现。Bonree ONE4.0的实时可用率监控,就是为了在问题爆发前给企业预警。
Q9:
Token消耗差距数倍这个发现,在规模化调用场景下,选最省和最费的模型,全年成本差异大概是什么量级?
A9:以本次报告数据为基准,完成同样一次任务:DeepSeek-v4-pro平均消耗约2680 tokens,Qwen3.6-plus约4930 tokens,比值约1:1.84。
按照一个中型企业每天API调用量1万次计算(这对许多智能客服、代码助手、自动化办公场景是保守估算):每日token差额约2250万tokens,全年差额约820亿tokens。以当前市场主流定价(综合输入输出约1-4元/百万tokens)估算,全年成本差异在8万到33万元之间。对于调用量更大的企业(如日均百万次调用),这个差距会放大至百倍,达到千万量级。
当然,成本只是一个维度。真正的决策逻辑是:用可观测平台持续追踪每个场景的"成本/质量比",找到最优平衡点,而不是一刀切选最便宜或最贵的模型。
四、Bonree ONE 4.0 AI可观测,
实现选型+运维全闭环
Q10:
本次发布的评测报告与Bonree ONE 4.0的AI可观测能力之间,是怎样的关系?
A10:评测报告解决"选哪个模型"的问题,AI可观测解决"选完之后怎么管好它"的问题。
评测报告是一个时间切片——它客观还原了2026年5月这个时间点,国内主流大模型公有云API的真实水平,给企业提供选型参考。但大模型服务是动态的,厂商持续更新版本,服务稳定性随负载变化,成本随调用规模变化。一次性的评测报告无法取代持续的监控。
Bonree ONE 4.0的AI可观测能力,本质上是把评测报告里的那套指标体系——首字响应、Token消耗、服务可用率、输出质量评分——搬进了企业自己的生产环境,实时持续地运行。
两者形成了一个完整闭环:报告帮你做初始选型,可观测平台帮你在生产中验证选型是否正确,发现问题并及时切换。评测过程中积累的方法论和数据,也直接反哺了产品的检测逻辑设计。
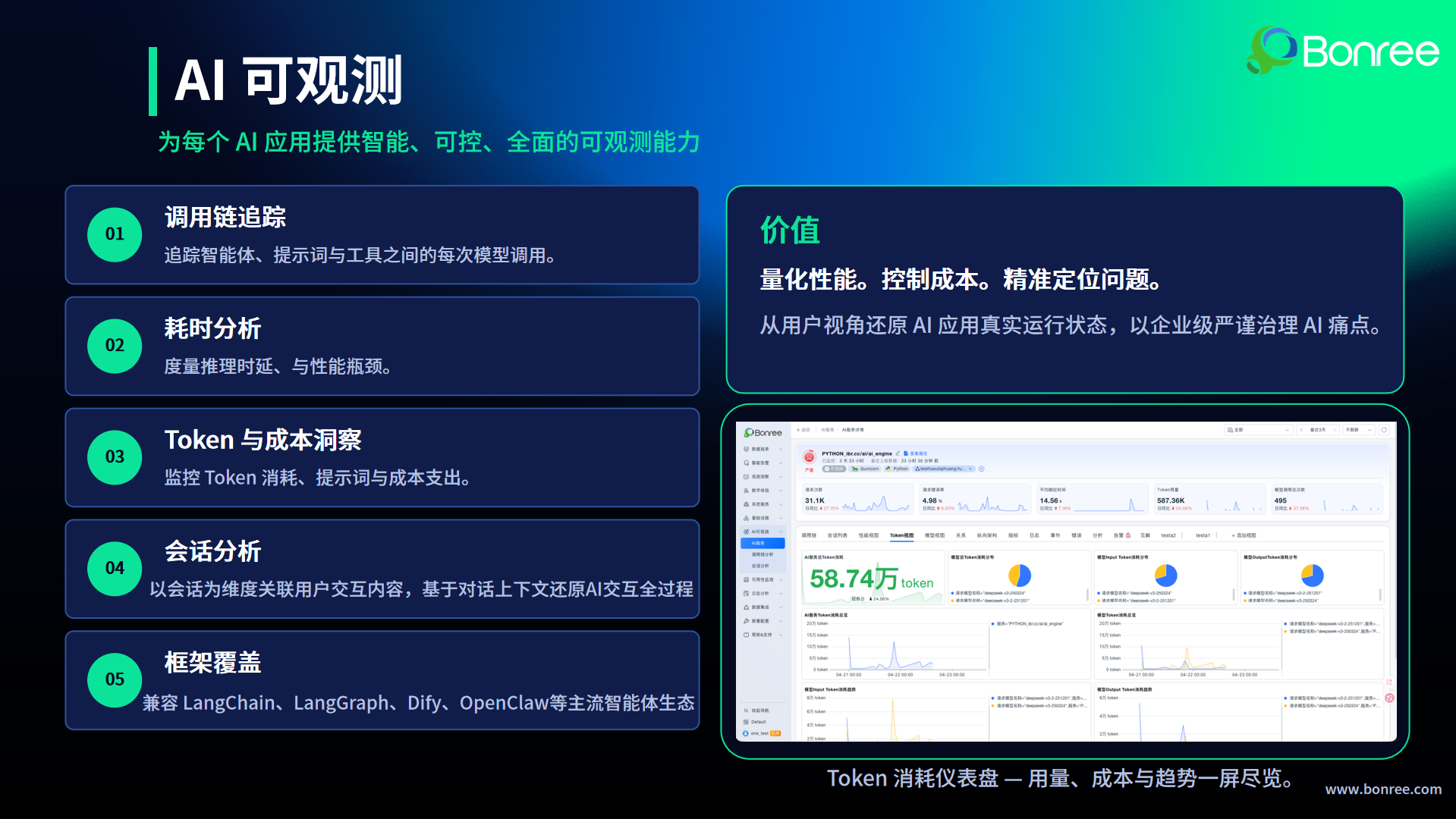
Q11:
Bonree ONE 4.0支持LangChain、LangGraph、Dify等主流Agent生态的原生兼容。对正在落地AI应用的企业来说,接入AI可观测的最大阻力通常来自哪里?
A11:我们在和客户交流中发现,接入阻力通常不来自技术复杂度,而来自认知层面的优先级排序。
最常见的阻力有三类:
第一,"先让AI应用跑起来再说"的心态。许多团队处于AI应用建设的冲刺期,把全部精力放在功能开发上,可观测被视为"锦上添花"而非"基础保障"。但往往等到生产事故发生、成本失控、用户投诉时,才会意识到可观测应该同步建设。
第二,与现有监控体系的整合顾虑。企业已有成熟的IT监控平台,担心引入AI可观测工具会造成"监控孤岛"。这正是Bonree ONE统一可观测平台的优势——AI应用观测与传统基础设施监控在同一平台管理,打通告警链路。
第三,数据安全顾虑。AI应用的调用内容可能涉及敏感业务数据,我们的解决方案是支持私有化部署和数据脱敏,在不牺牲可见性的前提下保障数据安全。原生支持LangChain等生态,就是为了让接入成本降到最低。
Q12:
AI应用的故障模式和传统IT故障有什么本质差异?AI可观测在解决哪些传统监控工具解决不了的问题?
A12:传统IT故障通常是"二元的"——服务正常或宕机,故障边界清晰,排查路径标准化。而AI应用的故障是"模糊的",主要体现在三个新型故障模式:
第一,质量退化。服务没有宕机,请求正常返回,但输出内容质量下降——出现幻觉、逻辑错误、任务完成度不足。传统监控看不到这类故障,因为HTTP状态码依然是200。
第二,成本失控型异常。某个Prompt设计缺陷导致Token消耗异常放大,服务看起来正常运行,但账单在悄悄爆炸。传统基础设施监控对这类问题完全无感。
第三,多跳链路故障。现代AI应用普遍采用多智能体串联架构,一个中间步骤的模型调用失败或质量下降,会在链路末端产生放大效应,但故障根因隐藏在中间某个LLM调用节点。
Bonree ONE 4.0针对这三类故障,提供了完整的会话树追踪、Token消耗异常检测、质量评分趋势监控。本质上是把监控的粒度从"基础设施层"下沉到"模型调用层",这是传统APM工具没有触达的领域。
五、展望未来:行业趋势与AI应用核心风险
Q13 :
报告得出"国内大模型已告别全能碾压阶段,场景化分化特征显著"。这种分化趋势会持续深化,还是会出现真正意义上的"全能模型"?
A13:个人认为分化会在中短期内持续深化,但长期来看会出现新的收敛——不是"全能模型",而是"高效路由层"。
分化深化的逻辑在于:不同任务类型对模型架构的要求存在内在张力。深度推理需要大参数量和长思维链,但这与低延迟、低成本需求天然冲突。在算力资源有限的前提下,针对特定场景做专项优化的模型,必然比追求全能的模型更有效率。
但这并不意味着企业要永远面对复杂的多模型选型矩阵。更可能的演进方向是:在应用层出现"模型路由层"——智能地根据任务类型、优先级、成本预算,自动分发到最合适的底座模型。这个路由层本身就是AI应用架构的核心能力,也是可观测平台需要支撑的关键场景。
对博睿数据而言,这个趋势意味着我们的评测工作会成为常态——每当新模型上线,企业都需要客观数据支持路由策略的更新。
Q14:
博睿数据如何将大模型API评测打造成长期有价值的项目?
A14:博睿数据的定位是建设一个持续运行的大模型服务质量观测基准。
具体规划包含几个层次:
频次层面,计划将报告发布从月度逐步扩展为更高频的动态数据服务,在重要模型版本更新后第一时间发布差异化对比数据;
维度层面,随着企业AI应用成熟,逐步纳入多模态能力、Function Calling精准度、长上下文稳定性等新维度;
生态层面,希望与开发者社区、行业协会合作,建立更开放的测评数据共享机制,让评测数据成为行业的公共基础设施;
产品层面,最终目标是让Bonree ONE平台上每一位用户都能看到自己所使用模型的"实时评测数据",而不是等一个月才看到一份报告。
持续的权威性来自一贯的客观性。我们在报告中展示了全部测评方法论细节,包括局限性,就是为了让这份报告经得起外部验证。
Q15:
站在智能可观测的视角,未来1-2年,企业AI应用的最大风险点是什么?
A15:我认为最大的风险不是技术风险,而是"可见性缺失"带来的管理风险——企业对自己运行中的AI应用,既看不清质量,也看不清成本,更看不清安全边界。
具体来说,有三个值得警惕的风险维度:
第一,AI成本黑洞。随着企业AI应用规模扩大,Token消耗呈指数级增长,而大多数企业目前没有精细化的成本追踪机制。一旦某个Prompt或业务场景触发了异常消耗,发现时可能已经超支数十万元。
第二,质量漂移。模型厂商静默更新版本是常见操作,版本更新可能带来某些场景质量的下降,如果企业没有持续质量监控,往往要等到用户投诉才能发现。
第三,多模型合规治理风险。随着多模型并用架构普及,哪个模型处理了哪类数据、是否符合合规要求,将成为监管关注的重点。这需要完整的调用链路审计能力,而不仅仅是应用层的业务日志。
这三个风险,恰好对应Bonree ONE 4.0 AI可观测能力的三个核心建设方向:成本可见、质量可见、链路可见。
点击下图或扫码下载《2026 年 5 月中国主流大模型 API 服务性能及综合表现测评报告》





