





一、报告前言
随着国内人工智能产业快速落地,大模型公有云API服务已成为企业智能化转型的核心基础设施,广泛应用于金融风控、智能编程、自动化办公等各类业务场景。截至2026年初,国内完成备案上线的大模型数量达数百款,市场呈现百花齐放的发展态势。
但行业乱象与痛点同步凸显,主流大模型API服务的性能、质量、成本差异极大。同一道算法题目,8个主流大模型产出8种差异化答案,代码完成度、逻辑准确性参差不齐;响应速度更是天差地别,头部模型首字响应不足0.5秒,部分模型则直接超时1分钟报错。由于企业仅能依托碎片化网络反馈、厂商宣传材料选型,缺乏客观、全面的实测数据,极易出现选型失误、业务适配不佳、运营成本过高、服务稳定性不足等问题。
基于此,博睿数据模拟企业真实智能体调用场景,开展大规模实测调研,正式发布《2026年5月中国主流大模型API服务性能及综合表现测评报告》。本次测评覆盖多核心业务场景与关键性能指标,客观还原各大模型公网真实服务水平,为开发者、企业架构师、技术决策者提供科学、精准的选型参考依据。
二、测评方案说明
2.1 测试场景与范围
本次测评选取中国多个核心城市,真实还原全国主流企业部署环境,于2026年5月持续实测,累计完成超1900次真实环境调用测试,数据样本充足、贴合商用实际场景。测评样本选取中国主流大模型公有云API服务,覆盖市场主流商用模型梯队。
2.2 评测核心维度与指标
本次评测围绕企业商用核心需求,搭建四大测评场景、三大评估体系,全方位校验模型综合能力。四大核心场景包括代码生成、数学推理、任务规划、幻觉控制;三大评估体系涵盖服务性能、输出质量、调用成本。核心观测指标包含服务可用率、首字响应耗时、整体响应耗时、生成速度、Token单次消耗、AI裁判专业质量评分等,确保测评结果客观、全面、可落地。
三、综合评分整体解读
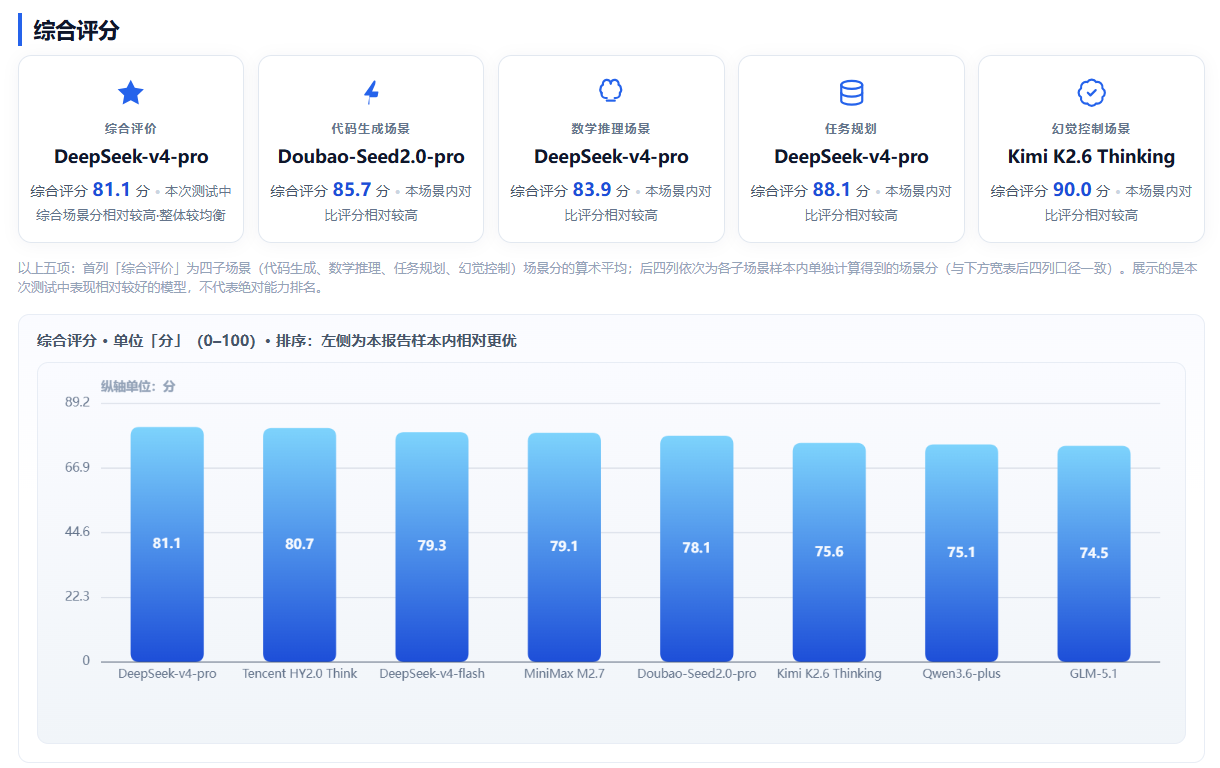
本次综合评分为四大核心场景得分的算术平均值,能够客观反映大模型API服务的整体商用能力。测评结果显示国内主流大模型无全能型选手,场景分化特征显著,各模型差异化优势明显。
本次测评中,DeepSeek-v4-pro以81.1分的综合评分位列第一,在代码生成、数学推理、任务规划三大场景中表现均衡,且消耗Token最低,服务稳定性突出,综合商用适配性较佳。
另外两个大模型在单独场景中表现亮眼:Kimi K2.6 Thinking(90.0分) :幻觉控制能力出色;Doubao-Seed2.0-pro(85.7分)代码生成能力突出。
核心共性关键发现
一是Token消耗差异悬殊。DeepSeek-v4-pro以单次平均2680 tokens成为全场最经济、高性价比模型,适配规模化低成本商用场景;Qwen3.6-plus(4930 tokens/次)、Tencent HY2.0 Think(4567 tokens/次)Token消耗量大,输出内容更详尽,适合高精度、高完整性内容生成场景。
二是整体可用率较高,复杂场景稳定性分化。部分大模型在基础场景可用率达 100%,但个别大模型在代码生成等高复杂度场景超时问题频发,Kimi K2.6 Thinking、GLM-5.1可用率跌破 70%,高峰期服务稳定性不足,不适用于高可靠、强实时的核心业务。
四、分场景详细测评结果
4.1 代码生成场景:Doubao-Seed2.0-pro 质量最优,GLM-5.1速度最快,部分模型超时严重
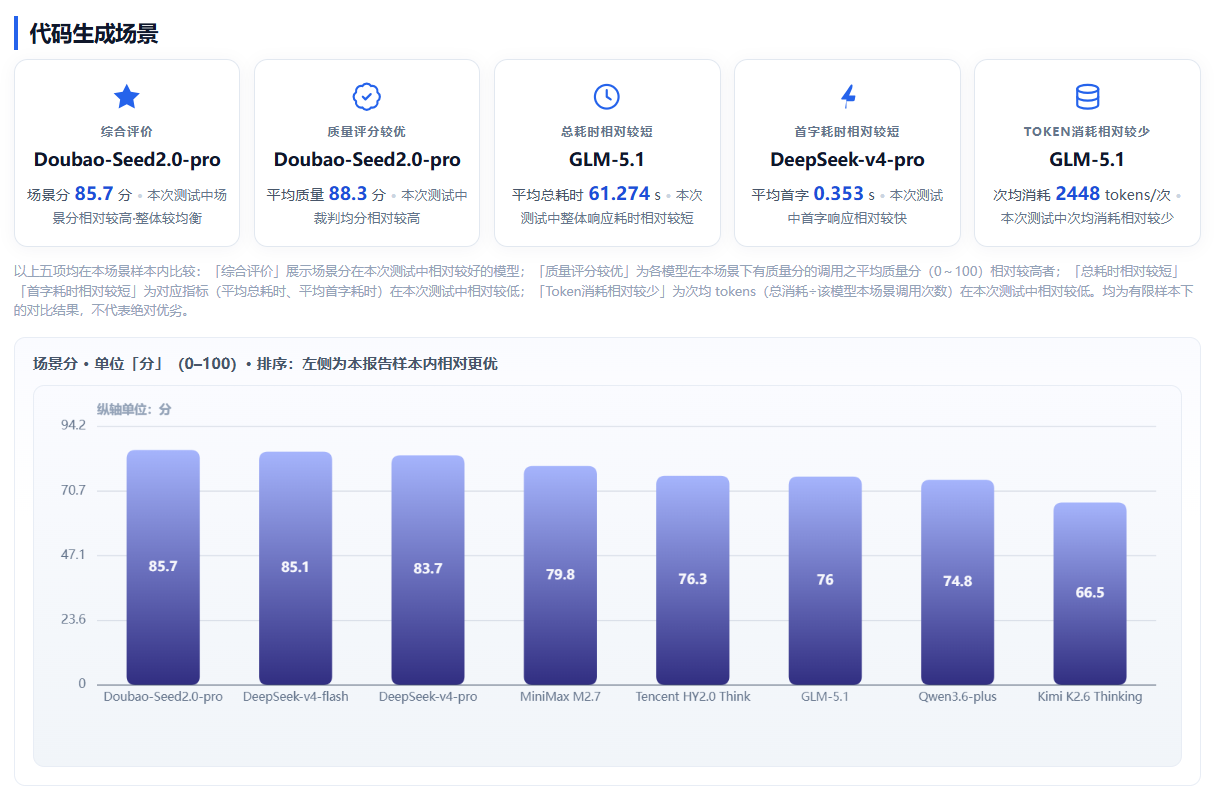
本场景聚焦模型代码需求理解、代码编写、纠错优化能力,是企业研发提效、智能运维、自动化开发的核心场景。测评结果显示,Doubao-Seed2.0-pro以85.7 分场景评分、88.3分质量评分领先,实现输出质量领先,适配企业高复杂性代码开发场景。
其他大模型表现呈现差异化:Tencent HY2.0 Think生成速度较快(136.23 tokens/s),DeepSeek-v4-pro首字响应最快(0.353秒),GLM-5.1总耗时最短(61.274秒),适合延迟敏感场景;DeepSeek-v4-flash、Doubao-Seed2.0-pro、Tencent HY2.0 Think表现稳定(可用率100%);Kimi K2.6 Thinking本场景可用率仅50%,超时问题突出,难以适配高强度代码开发场景。
4.2 数学推理场景:DeepSeek-v4-pro领跑
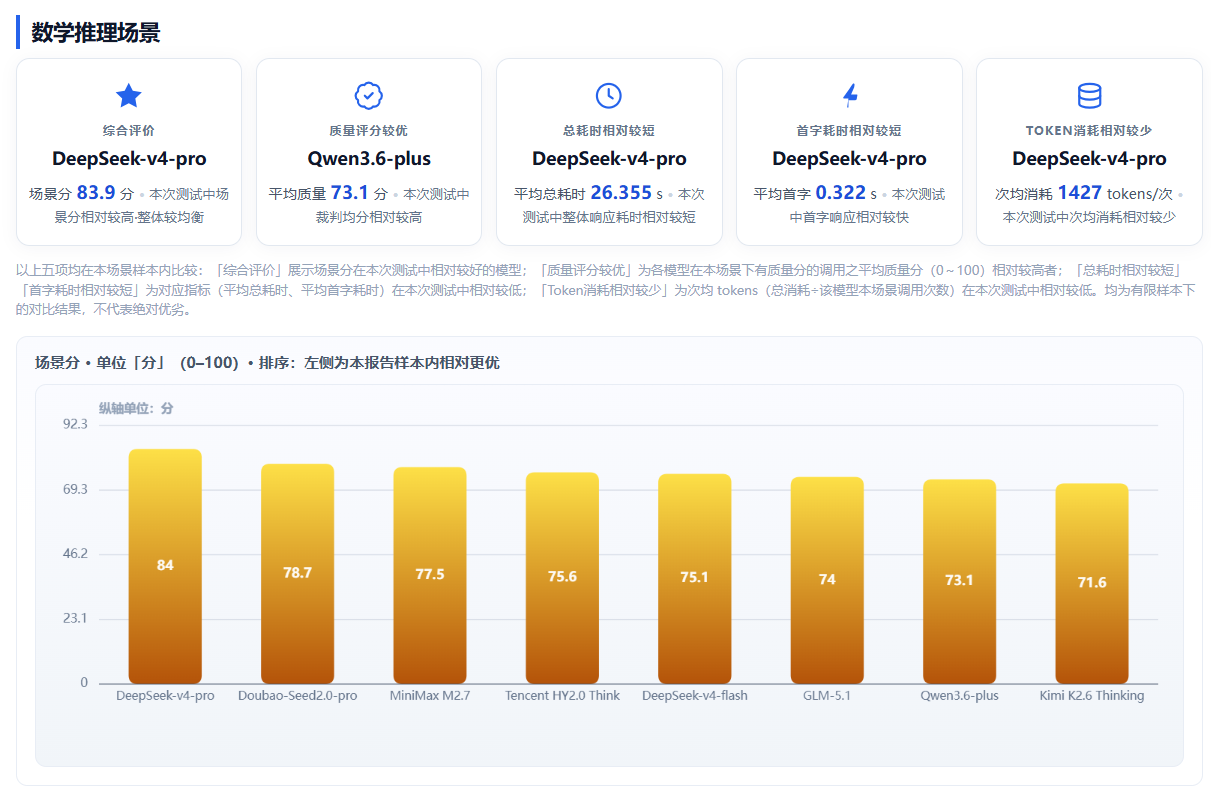
数学推理场景侧重校验模型数值计算、逻辑推导、复杂问题拆解的准确性,是金融测算、数据分析、科研辅助等场景的核心能力。本轮测评中,DeepSeek-v4-pro 以83.9 分场景分领先,平均总耗时 26.355秒、首字 0.322 秒、次均 Token1427 个,速度、成本最优。Doubao-Seed2.0-pro 以 78.7 分位列第二,数学推理相对出色。
4.3 任务规划场景:DeepSeek系列领跑,Tencent HY2.0 Think紧随其后
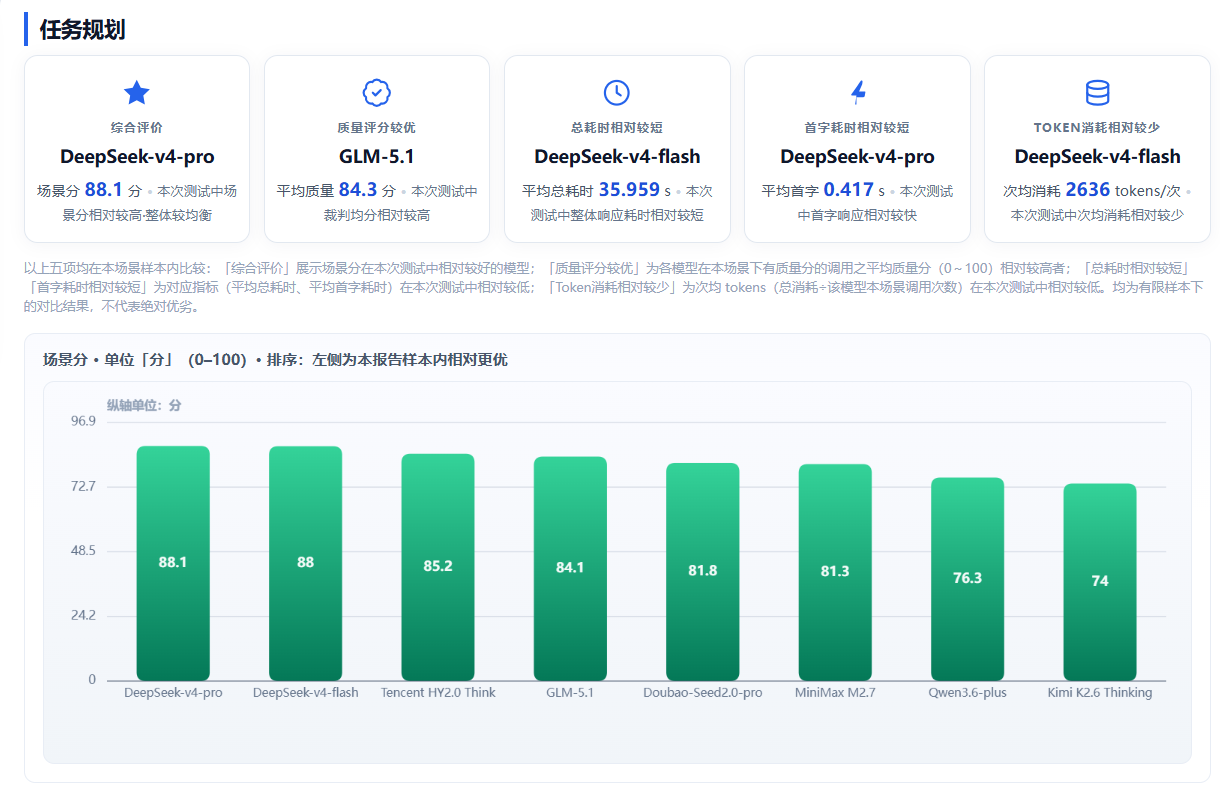
任务规划场景考核模型对多约束、多步骤、复杂综合性任务的拆解、编排、落地能力,是智能体调度、自动化办公、流程规划等高阶 AI 应用的核心支撑。本次测评中,DeepSeek-v4-pro以88.1分、 DeepSeek-v4-flash 以88分位列第一、第二,在复杂智能体任务编排、多步骤任务拆解领域具备较大优势。
Tencent HY2.0 Think以85.2 分位列第三,质量评分 81.2 分,任务规划完整性优秀;GLM-5.1质量评分84.3 分,为本场景质量最优,输出内容贴合需求。
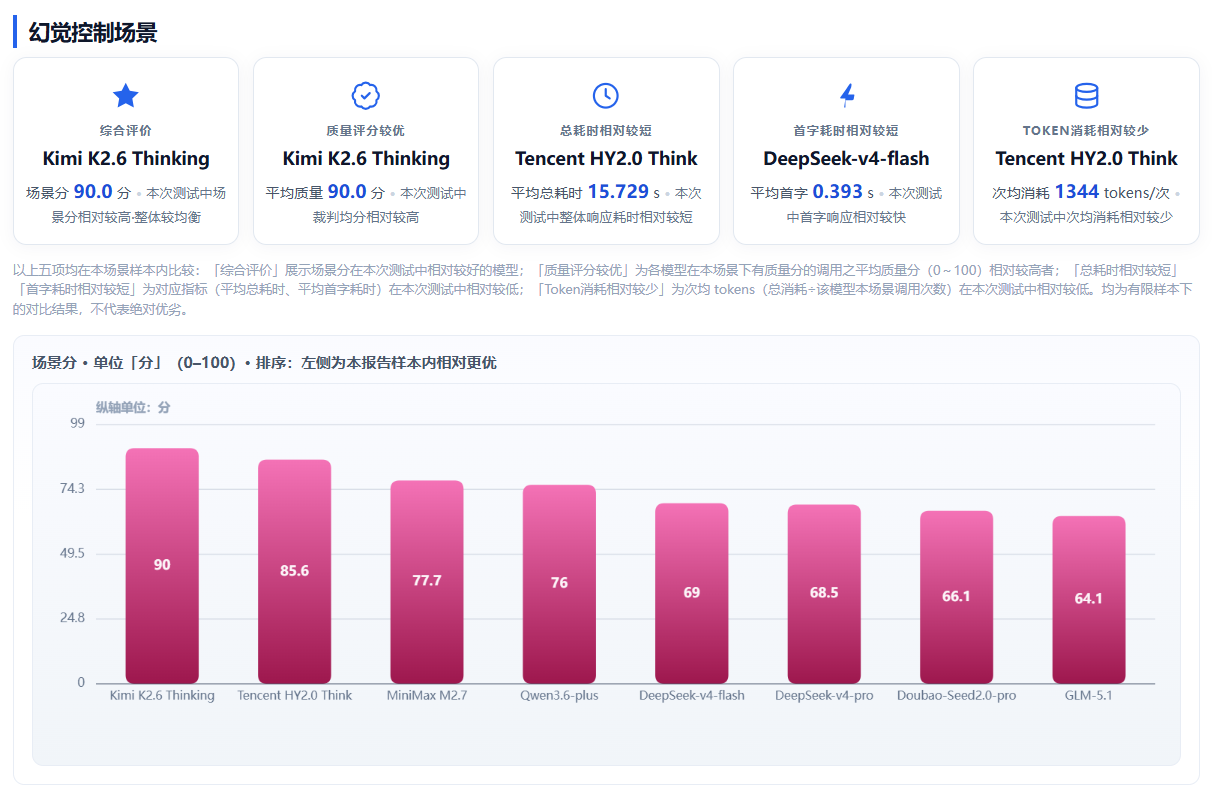
4.4 幻觉控制场景:Kimi K2.6 Thinking全场第一,准确性能力凸显
幻觉控制是衡量模型规避捏造信息、精准应对未知问题的核心指标,直接决定金融咨询、知识问答、内容审核、舆情分析等严谨场景的落地效果。本场景仅采用质量评分作为最终得分,无性能指标加权,更贴合业务需求。
测评结果显示,Kimi K2.6 Thinking以90.0 分位居全场第一,面对未知问题时输出审慎、精准,捏造概率较低,内容输出可靠性强。Tencent HY2.0 Think以 85.6 分位列第二,幻觉控制能力同样处于行业上游水平。
五、行业核心趋势与测评总结
5.1 行业核心趋势
1. 模型能力场景化分化,无通用全能型模型。
当前国内大模型 API 服务已告别 “全能碾压” 阶段,各模型依托技术定位形成差异化优势:Doubao-Seed2.0-pro代码生成能力最强; DeepSeek-v4-pro 数学推理、任务规划能力出众;Kimi K2.6 Thinking幻觉控制表现优异;企业需摒弃 “一刀切” 选型思维,按需匹配场景模型。
2.服务稳定性与任务复杂度强相关。
基础的知识问答、幻觉控制场景整体可用率高、运行稳定;代码生成、数学推理等复杂场景,普遍出现可用率下降、超时报错、限流等问题,是企业业务落地的主要风险点。
3.Token 效率与可用率成为规模化商用核心指标。
不同模型同等任务下 Token 消耗差距数倍,小规模调用差异可忽略,但企业规模化、高频次调用场景下,Token 效率直接决定运营成本;高可用率则保障业务不间断运行,二者成为企业选型关键。
5.2 整体总结
本次测评所有数据均来自2026年5月公网真实采样,客观还原了国内主流大模型公有云API的真实商用水平。整体来看,国内大模型API服务已实现规模化落地,但能力不均衡、可用性差异大、成本差异大等问题突出。
对于企业而言,大模型选型不再是单纯比拼综合评分,而是基于自身业务场景的精准匹配:代码开发优先选择Doubao-Seed2.0-pro;数学推理优先选择 DeepSeek-v4-pro;复杂任务规划可优选 DeepSeek系列;知识问答、严谨内容输出可优选 Kimi K2.6 Thinking;全场景均衡、高稳定优选 DeepSeek-v4-pro。
本报告旨在为行业提供客观、真实的选型参考,助力企业搭建高可靠、高质量、低成本的AI应用,降低AI集成风险,提升AI业务落地效率。
六、Bonree ONE 4.0 重磅升级,AI可观测助力AI应用稳定运行
博睿数据最新发布的Bonree ONE 4.0深度融合AI技术,直面企业在AI投入效果、成本消耗、故障排查等方面的核心痛点,革新AI可观测能力,打造完整的AI应用观测栈,核心包含模型调用链追踪、延迟分析、Token与成本可见、输出质量分析四大能力,原生兼容LangChain、LangGraph、Dify等主流Agent生态,实现每一次LLM调用全过程的可控、可视。
同时,平台支持多类型大模型统一治理,覆盖GPT系、通义千问系、DeepSeek系等公有、私有模型。实时监控Token消耗趋势,精准定位异常失控Prompt;依托会话详情,生成完整会话树,逐轮记录对话、工具调用流程,细化Token消耗与延迟画像,用量化的方式管控AI性能、成本与故障,告别经验化运维,让 AI 应用稳定运行。
点击下图或扫码下载完整报告,获取各模型详细评分与性能数据。




