




作者:博睿数据数智能力中心 DRay
背 景
在信息爆炸的时代,我们穿梭于无数的应用与数据面板之间,常常像一个迷失在数字丛林里的探险家。想象一下:假如你刚刚接触功能强大的Bonree ONE运维平台,想找到"全局拓扑图"的功能,但面对Bonree ONE平台的众多具体功能页面,你却只能像在迷宫里打转——它到底藏在"观测洞察"页面还是"数字体验"页面里?
再想象一下:在某个具体故障发生时,你想编写一个PromQL语句来查询某个服务的接口错误率或者某个主机的最近5min的CPU使用率变化,但着急忙慌中,你的大脑一片空白——那个查询接口错误率的语法到底是什么来着?rate()还是irate()?时间窗口该设置多长?
这些都是技术人员日常工作中的真实痛点。而小睿助理的要做到的,正是为了让这些令人抓狂的时刻成为过去式。

小睿助理的功能
小睿助理是一款基于大语言模型(LLM)的智能助手系统,它不仅仅是一个简单的问答机器人,而是一个真正"懂你"的技术伙伴。它能够:
意图识别。精准理解你想要做什么;
PQL生成。快速生成复杂的PromQL监控查询语句;
智能导航。导航帮你找到所需要的Bonree ONE平台具体功能页面;
环境感知。上下文感知到你当前在哪个页面,该页面有哪些功能;
智能问答。基于运维领域知识,可观测领域知识,Bonree ONE平台的功能点,智能回答各种技术问题。
小睿助理内部原理
小睿助理结合了大语言模型(LLM)和检索增强生成(RAG)技术,它先利用LLM对用户提问进行意图识别,然后根据意图分流至不同的功能模块:PromQL 生成、环境感知、功能导航和智能问答。这些功能的底层原理都是将用户输入及相关知识通过文本嵌入(将文本转为向量)和向量数据库检索结合,在此基础上由LLM生成最终回答,其流程就是目前主流的RAG技术流程。
小睿助理内部使用RAG技术主要分为两个阶段,如下图所示:
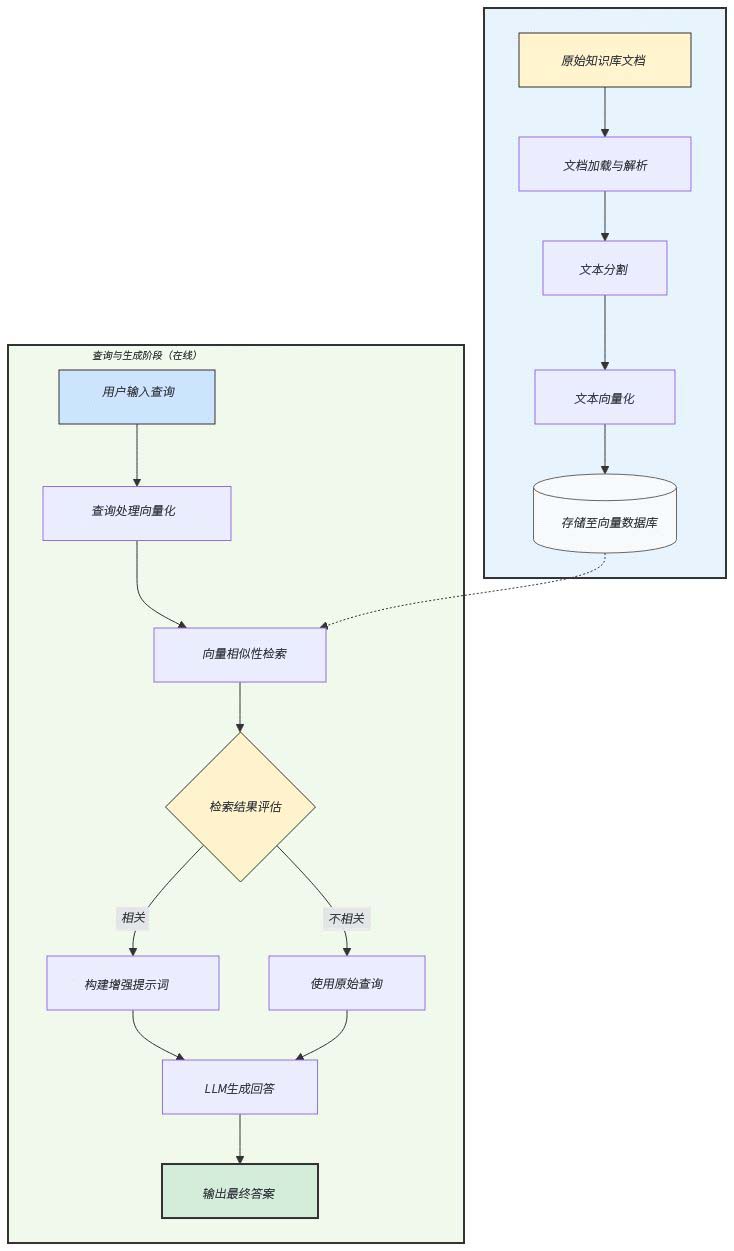
1. 索引构建(离线处理)
此阶段是为知识库建立可快速检索的索引,通常只需执行一次或定期更新。
文档加载与解析。
输入:来自各种来源的原始知识库文档(如 PDF、Word、HTML、Markdown、数据库)等。
过程:使用文档加载器读取并解析文件,提取出纯文本内容。
文本分割。
过程:将长文档分割成更小的、有意义的文本块。这是关键步骤,因为 LLM 有上下文窗口限制,且小块文本更易于精准检索。
文本向量化。
过程:使用嵌入模型将每个文本块转换为一个高维向量。这个向量在数学上代表了文本的语义信息,语义相近的文本其向量在空间中的距离也更近。
存储至向量数据库
过程:将文本块、其对应的向量以及可能的元数据(如来源、标题等)一起存储到向量数据库中。
2. 查询与生成(在线处理)
此阶段在用户每次提问时实时发生。
查询处理与向量化
过程:针对用户提出的问题,使用与索引阶段相同的嵌入模型,将用户问题也转换为一个向量。
向量数据库检索
过程:在向量数据库中,通过计算余弦相似度或欧氏距离等度量方法,寻找与查询向量最相似的 Top-K 个文本块。
结果评估与提示词构建
评估:小睿会使用ReRanker模型来对检索到的结果与用户问题进行相关性排序。如果相关,则进入下一步;如果完全不相关,系统会告知用户知识库中没有相关信息。
提示词构建:将检索到的相关文本作为“上下文”或“参考信息”,与用户的原始查询一起,精心构建成一个最终的提示词。
LLM 生成回答
过程:将构建好的增强版提示词输入给大型语言模型。LLM 会基于其内部知识和对所提供上下文的理解,生成一个精准、可靠的答案。
意图识别功能
用户提问后,系统首先要判断"你想干什么"。这个判断过程使用LLM进行分类,将用户问题提供给LLM,并在提示词中预先设置为几种不同意图,由LLM理解用户问题,并对问题进行意图分类,例如:
"如何查询Pod的内存使用率?" → PromQL生成
"当前页面是做什么的?" → 环境感知
"拓扑图在哪里?" → 智能导航
"什么是Prometheus?" → 智能问答
这就像医院的导诊台,先判断你应该去哪个科室。
PQL生成功能
如果意图识别结果表明用户需要查询监控指标数据(PromQL 生成功能),系统会按照以下流程生成PromQL查询语句:
用户问题向量化。将用户的自然语言问题输入嵌入模型,得到一个向量表示。
指标检索。使用该向量在Milvus向量库中执行相似度搜索,找到Top 20个与问题语义最相关的指标信息(如指标名称和描述)。
重排序(ReRank)。对这20个候选指标使用重排序模型进行再次排序,筛选出Top 10个更精确匹配的问题语义的指标及其对应的示例PromQL查询。
Few-Shot 提示构建。将上述10个指标的信息和示例PromQL作为few-shot示例拼接到提示词中(例如以“示例:输入→输出”形式附加到用户问题前)。
LLM生成PromQL。将包含用户问题和few-shot示例的完整提示发送给大语言模型,LLM根据上下文归纳出满足用户需求的最终PromQL查询语句。
整个过程中,系统相当于先“检索”相关指标(向量搜索+重排序),再让LLM生成最终答案,是典型的检索增强生成(RAG)模式。
其内部转换流程为:
步骤1:用户提问,比如:"查看过去5分钟Nginx的QPS";
步骤2:向量化用户问题,Embedding模型将问题转换为1024维向量;
步骤3:向量检索,在Milvus中查找Top20相似的历史指标,比如查询到的历史指标信息为:
- 指标名称: nginx_http_requests_total
- 指标说明: Nginx HTTP请求总数
- PromQL示例:
rate(nginx_http_requests_total[5m])
- 相似度: 0.89
...
步骤4:智能重排,使用ReRanker模型深度评估,筛选出Top10,其作用为:
- 过滤掉表面相似但语义不符的结果
- 重新排序,最相关的排在前面
步骤5:Few-shot推理,将Top10作为示例交给LLM,提高生成的准确率,比如:
"参考这些例子,生成查询Nginx QPS的PromQL"
步骤6:生成最终结果,如下:
sum(rate(nginx_http_requests_total{job="nginx"}[5m]))by (instance)
其他功能
其他三个功能:智能导航,环境感知,智能问答的具体技术原理和上述PQL生成类似,不同点在于:
在智能导航和环境感知功能中,首先需要构建Bonree ONE每个页面的知识库:收集Bonree ONE页面上每个具体页面的URL、导航路径、功能介绍、详细内容和概要总结等信息。将这些内容(网页摘要、功能说明等)输入嵌入模型生成向量,并存入Milvus数据库。这样,每个页面都对应一个或多个向量记录,形成页面知识库。
在智能导航功能中,在提供给LLM的提示词中,需要输入用户询问的页面的URL地址,导航路径等内容,这样LLM在进行回答时,会参考提示词中的页面地址和导航路径,回答的问题中会详细列出导航的页面地址。
总 结
小睿助理的设计哲学可以用一句话来概括:"让复杂的技术变得简单,让简单的操作变得自然!"。
它不是要取代技术人员,而是要成为每个Bonree ONE使用者的"超级助理"——就像钢铁侠的贾维斯,哈利波特的魔杖,让专业的人可以更专注于创造性工作,而把重复性的、记忆性的任务交给大模型。
当凌晨三点告警响起时,你不再需要翻遍文档寻找那条PromQL语句;当新人入职时,他不再需要花一周时间摸索系统功能。小睿助理会像一个经验丰富的老员工一样,随时随地提供帮助。
这就是小睿助理带来的温度——不是冰冷的代码,而是贴心的伙伴。




