




















Bonree ONE Sage AI运维智能体工作台是博睿数据基于AI可观测平台打造的智能体运维中枢,它能够将整条业务链路图读成一份可执行的诊断报告,让风险定位从“多页面反复横跳”压缩为“一次点击”。
一、为什么业务链路拓扑图显示告警但整体可用性正常?
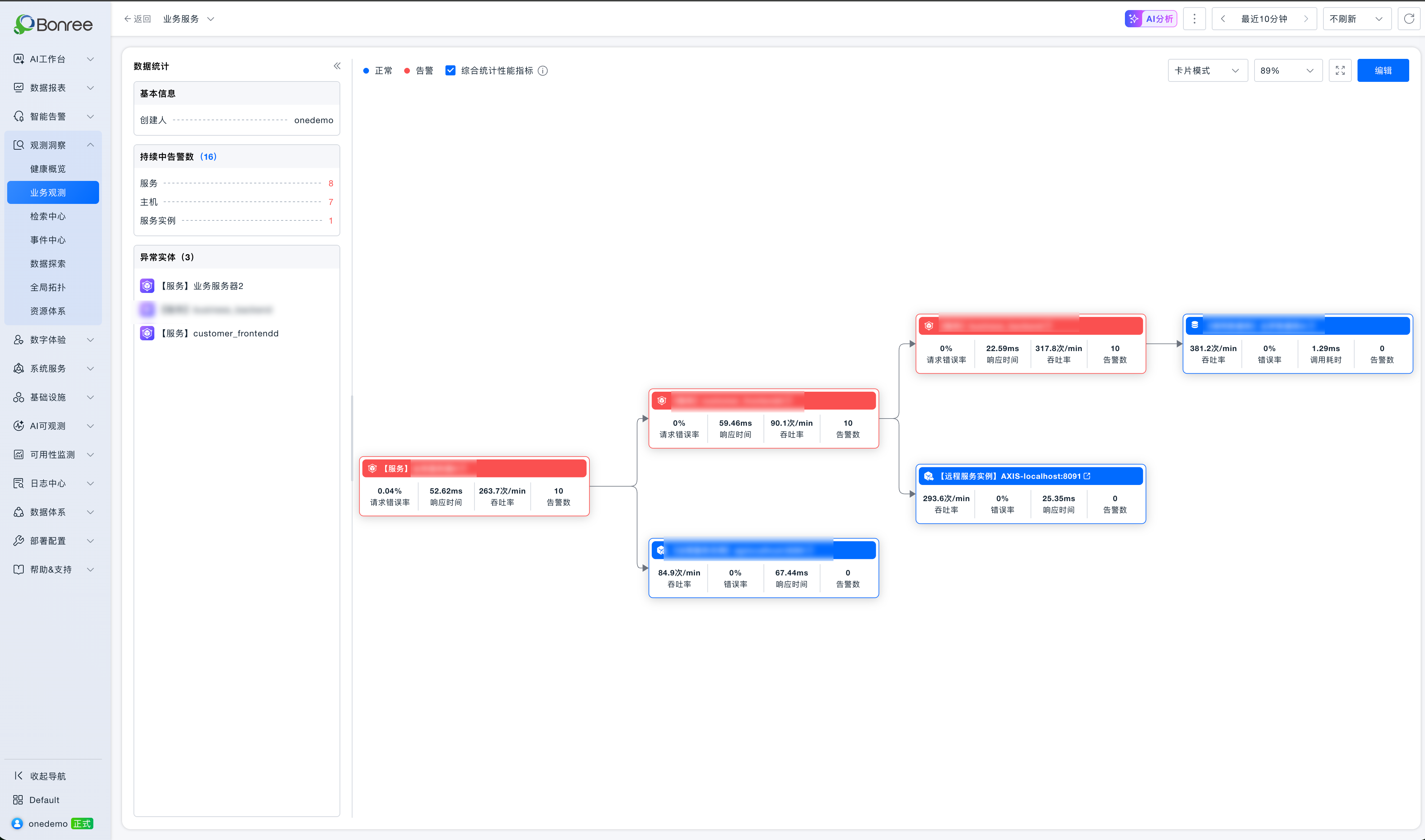
这是一条真实的业务链路(链路 ID:1611)。入口的“业务服务器2”调起 customer_frontendd、business_backend,再经 RPC 远程服务,最终落到达梦数据库 A。拓扑图上三个服务节点同时标红、持续告警共 16 条;
可奇怪的是,链路整体可用性并不差——错误率几乎为 0,响应时间都在几十毫秒,Apdex 接近 0.99。到底哪里有问题、要不要救?过去这需要 SRE 在拓扑、指标、日志、告警、变更记录之间来回切换、逐个排查。现在,点一下“AI 分析”,Bonree ONE 的Sage AI直接定位风险点。
二、 Sage AI的健康分析如何顺着调用关系层层缩小嫌疑?
Sage AI的健康分析模块将整条链路视为一个整体,通过横向与纵向拓扑推理,结合可观测数据交叉验证,层层剥离噪声,精准锁定根因。
Sage AI不是单看某一个指标,而是把整条链路当成一个整体来推理。它先看横向拓扑:
● 入口的“业务服务器2”有 7 个错误请求(错误率 0.04%),而下游 customer_frontendd 和 business_backend 的错误率都是 0——这说明错误是入口节点自身抛出的,并非下游传染。
● AI 于是“停止下钻”,把嫌疑直接锁定在业务服务器2,省去了沿链路逐个排查的功夫。接着它下钻纵向拓扑,发现一个肉眼很难察觉的隐患:三个服务的核心实例都集中部署在同一台主机 onedemo-k8s-node2 上,而这台主机自身就带着 7 条未解决告警——这是集群级的单点风险,而非单实例故障。
● 再配合可观测数据(USE/RED + 日志 + 告警)交叉验证:近 1 小时三个服务都没有 error 级日志,20 条检测事件全是接口 RT 略超 10ms 阈值的周期性波动、且多次自动恢复,AI 据此判断这是阈值过敏的告警噪声,而非性能雪崩。
三、 变更分析如何排除“刚改了什么”的干扰?
Sage AI的变更分析模块自动关联发布、配置变更与扩缩容记录,快速排除外因变更,使异常定性聚焦于运行时慢性问题,避免误判。
健康只是问题的一半。Sage AI同时做了变更关联——查询近 1 小时链路上的发布、配置变更与扩缩容记录,结果是“无外因变更”,仅有系统自动产生的检测事件。
这一步很关键:它直接排除了“刚上线什么导致故障”的可能,把异常定性为运行时状态下的慢性问题,而非变更引入,帮 SRE 少走一大段弯路。
四、 Sage AI如何将链路图转化为可执行的诊断报告?
Sage AI最终输出一份按优先级排序的可执行诊断,涵盖根因、影响范围和具体动作,让运维人员从“看拓扑”升级为“读答案”。
几分钟内,Sage AI就把这张链路图读成了一份可执行的诊断:
● 根因:入口业务服务器2 自身的错误请求 + 三服务共享主机的单点风险
● 影响范围:整条 1611 链路及主机级波及
● 以及按优先级排好的动作——
○ P0:定位 7 个错误请求来源、排查主机 7 条告警
○ P1:评估那条已持续 3.67 天的响应时间告警阈值是否过敏
○ P2:复盘 RT 阈值与服务拆分
它把 SRE 原本要在多个页面间反复横跳的排障过程,压缩成一次点击。
链路图不再只是“看”,而是能被 AI 读懂、并给出答案。
Last Updated: 2026年6月16日 · Bonree ONE 4.0.0.7
版本说明:本文基于 Bonree ONE 4.0.0.7 版本(2026年6月16日更新)撰写。该版本包含 Sage AI智能体运维工作台、APM、RUM、SDK、Alert、Analysis、Event、CMDB、ETL、IAM 等能力模块的同步升级。




